くまりゅう日記
2023-02-07
日記
ぐえ、もう2月だ。
だいたい書くこと貯まるのは日曜までなので月曜くらいに日記書きたいところではあるが、月曜夜はだいたいゲーセンに行ってるのでなかなか書けない。
[模型] 30MS ルルチェ
30MSのオーディションとやら(公式コンペ)やってるので出すもの作ろうとやっていた。
適当にがちゃがちゃいじってたらいい感じになった。

腰周りに何か付けたいなあということで爪付けたり、メカニカルユニットの腕は脚にもできるんじゃねえかと付けてみたら付いてのでそれにしたり、せっかくなので胸もなんかつけるかとシエルノヴァのアーマーを付けて肩にもつけたらいい感じに。背中はどうしようかなあとちょうどその時組んだばっかりの大型プロペラントタンクつけてみたらちょうどよかったのでそれにしたり。かなりいきあたりばったりで組んだけど結構まとまった。手持ちは最初ラビオット武器セットの手裏剣の欠片みたいなのを持たせたんだが1個しかなかった。探したらちょうどいいことにエスポジットの銃があったのでこれに落ち着いた。
なんか色塗らずにもうこれでもいいんじゃねえのという感じもしたんだけど、さすがにオレンジは派手だしふともものグレーや銃のグレーもなんとかしたいなあということで検討することに。
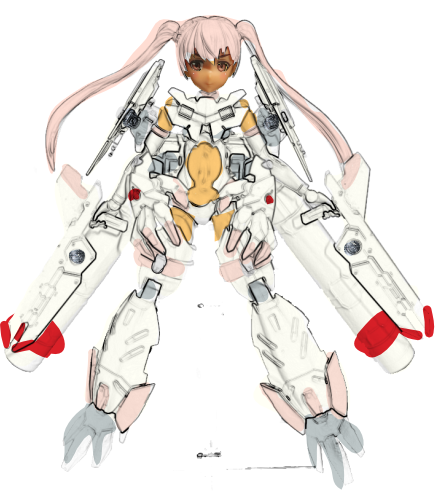
宇宙仕様な感じでいきたいが、それっぽい色だと白・グレー・オレンジくらいしか思いつかない。オレンジはちょっと目立ちすぎるし、他が白とグレーだけだと地味すぎる。頭がピンクなのでそれに合わせとくかということで浅い色のピンクを基調にすることにした。あと派手な色も一部入れた方が締まるよねえということで赤をアクセントに。全体的に末広がりなシルエットなので先端付近を赤にしよう。
で塗りました。





腰の爪パーツには最初3Dレンズシールを貼ろうと思ったんだけど、4mm径と5mm径のしかないのでちとでかすぎる。3Dメタリックシールだともうちょっと小さいのあるからこっちではどうかな?と試してみたらいい感じになった。カスタマイズマテリアルシリーズはこないだ出たばっかりなのでせっかくなので使おうとしたが、結構使うの難しいよなあ……。
撮影は簡易的にやっただけなのでまたちゃんと撮影したら応募しましょう。 爪パーツとかスラスターとか結構広い範囲で動くんだけど、それも見せられるようなポーズで撮りたいところ。
ところで公式ルール的にはパーツの切り貼りOKなんだけど、俺ルールとしては切り貼り無しで作ることにしているので今回もパーツを普通に組み合わせるだけで作ってます。パズル楽しいもんね。なお合わせ目消しで接着はしたけど形状変わるものではないのでOKとする。
[プログラム] Speech to text その2
unacastにAzureのSpeech to textを使ってしゃべったのをテキストとして表示する機能を追加したんだが、有効にしてる間お金がかかるという問題があって、これで破産しそうである。うそ。破産する程高くはないが1時間$1かかるのでまあまあお金が持っていかれるのである。
方法としては別な無料で使える何かを使うか、実際にしゃべってる間だけAzureに接続して節約するかだが、Windows標準のSpeech to textが精度良さげ(というかAzureのSpeech to textに接続してるっぽい)なのでこれを使えるか試してみたい。 WinRTのAPIではあるが、NodeJSからWinRTに接続できるライブラリはあるのでなんとかなるんじゃないか?
ドキュメントを読むとWindows.Media.SpeechRecognitionはパッケージ化されたアプリでなんか権限を得ていないと使えないみたいなことが書いてあって先行きが不安だったが、とりあえずC#のコンソールアプリでやってみると普通に動いてくれた。問題なさそうだ。
では、ということでNodeJSのunacastから呼び出してみるが、なんだか一見動きそうだけどすぐに止まってしまう。どうもユーザーキャンセルで止まっているらしいんだが、誰もキャンセルなんかしていない。というかキャンセルのAPIなんか呼んでねえのになんでキャンセルされるんだ?一応キャンセルされたら再度認識スタートさせてみるが、なーんも動かん。しかしたまに動いてるふりも見せてくるので謎すぎる。C#のコンソールアプリではちゃんと動くんだけど、やってることはそんな違いないと思うんだけどなあ……。
で、しばらくああでもないこうでもないと困っていたんだが、たまーに上手くいくパターンを見つけて観察してたら気付いてしまった。ウィンドウのフォーカスが外れると認識キャンセルされるんだ!!C#のコンソールアプリはそこしか見てないから気付かなかったけど、unacastだとGUIの開始ボタンを押したあと認識結果を見るのにコンソールにフォーカス移してたのでキャンセルされていたのだった。
調べてみるとフォーラムで同じこと質問してるのが見つかったけど、フォーカス外れても認識続ける方法ないの?→ないです→なんでそうなってんの?→仕様です。ということだった。いやー仕様なら仕様でいいんだけどさ……じゃあドキュメントに書いとけよ!!!こちとら何時間悩んだと思ってんだ!!!!!!
まあAzureで有料で使えるSpeech to textと同じものが無条件で使い放題なのおかしいっすよねとは思ったよ……。
他の方法として最近ReazonSpeechというのが無料公開されているのを知った。デモでの認識も十分良さそうなので、これ組み込めたら無料でいい感じにできそう! でもESPnetとかいうやつのモデルで公開されてて、その辺全然わからんのでそう簡単に組み込みってわけにはいかんか……。まあいろいろ調べてみよう。
なおまだしばらくお金がかかるままで配信しています。
[プログラム] Text to speech
逆にText to speechを組み込むのも始めてしまった。
見てた配信でunacastで読み込んだレスをずんだもんに読み上げさせるのにunacastと棒読みちゃんとVOICEVOXを起動していると聞いてそれは大変だなあと思ったのがきっかけ。 あとSpeech to textで認識させたテキストを読み上げに渡す機能も作ってはあったんだが、読み上げの設定がめんどくさくて試してなかったってのもある。
VOICEVOXは調べてみるとHTTPで接続して機能を呼び出せるようになっているらしい。それをWindowsの読み上げ機能を使って呼び出すプラグインっぽいのを入れて棒読みちゃんからそれを呼び出してるっぽい。くっそめんどくせえことやってるな。 まあHTTPで接続できるならunacastから直接それを叩けばよかろう。
早速コードを書いてみたんだが、いざ実行してみたらfetchがないとか言われる。え?外部のAPI叩くのにfetch関数使ったんだが、unacastが使ってるElectronが古すぎてfetchなかった。まじかよ。他の場所ではaxiomとかいうのが使われていたが、あんま詳しくないのでめんどくさそうだ……。
ということでその日は遅くなったのでそこで諦めた。
後日気付いたんだが、VOICEVOXはHTTP経由でなくてもC APIが定義されているのでDLLを読み込んで直接呼び出すことができるのではないか?どうも調べたらできるっぽい雰囲気なのでそれを試してみよう。これならHTTP叩く必要ないし、VOICEVOXを起動する必要もないはず。
まずC#で試しに書いてみたが、さっくり上手いこと動いたように見える。 じゃあNodeJSでも同じことをやってみよう。FFIがちょっとめんどくさいが、まあ使うAPIはそんなにないのでなんとかなるだろう。 と思ったんだが、なんか初期化関数呼んだだけでクラッシュする……。なんだかバージョン違うみたいなログが一瞬表示されているが意味わからんし……。 だいぶいろいろ試してみたが、どうもDLLの読み込み方がなんか悪いっぽい?というのはわかったがどうすればいいのかわからなくて夜遅くなったので一旦打ち切り。
次の日見たらちょうどVOICEVOXのバージョンが上がっててAPIの仕様も変わっていた。 新しいのだと上手くいくかなあと試してみると、やっぱりクラッシュはするもののログがもっと出るようになっててわかりやすくなっていた。 どうもクラッシュはONNXRuntimeの初期化時に起きてるらしい。あーバージョン違うってのはまさかこれか? VOICEVOXのインストール先にあるonnxruntime.dllは1.13.~というバージョン、読み込んだonnxruntime.dllはSystem32にある1.10.~というバージョンだ。 あー古いバージョンの読み込んじゃってるからバージョン違うってのが出てクラッシュするんですねそうですね。 調べると、どうもonnxruntime.dllはシステムにあるのは使っちゃだめです、自前で配布してくださいって書いてあった。 クソMSはシステムディレクトリに入れちゃいけないDLLをシステムディレクトリに平気で入れてるのでいろんなアプリが苦労してるようだ。ひでえ。
DLLのロード方法を工夫すればなんとかなるっぽいんだけど、libffiからいじらないとだめっぽいのでちょっと大変だなあ。あとは既にDLLを読み込んであればそれを優先してくれるということなので、じゃあonnxruntime.dllを先に明示的に読み込んじゃえばいいか……。ということでやってみたら上手くいった。やったー!
初期化はできるようになったのであとは粛々とAPIを呼び出していけばいいだけ。 もう困ることはないはず……とやってみると、なんか推論失敗とかで音声返してくれないなあ。 しかしCPUモードにしてみると通ってくれた。うーん、やっぱりなんか読み込みに失敗してるのかもしれん。 ちなみにVOICEVOXの単体起動だとちゃんとGPUモードで動いてくれるのでGPUモードが全く使えてないというわけではない。
調べるの大変だしまあ当面はCPUモードでもいいか。先に進めよう。
VOICEVOX Coreから受け取ったWAVをAudio要素に渡すのにちょっと手間取ったところはあるが、それでもまあそこまで時間かからずに動かすことに成功。 読み込みパスや読み上げ設定なんかはまだ全然固定だけども、VOICEVOXはインストールしとくだけ、起動するのはunacastだけでずんだもんでの読み上げができるようになった。
誰でも使えるようにするのはいろいろ設定できるようにしないといけないが、まあそこはめんどくさいところではあるが難しくはないのでぼちぼち進めればいいでしょう。 ひとまず動くものはできたので目処はたった。
しかしCPUモードだとやっぱり遅延がだいぶでかい。そんなレス激しい配信してないし読み上げなのでちょっとくらい遅れても問題はないんだが、ちょっとでも長いテキスト渡されると10秒とか遅れて発音されるのはさすがに気になってしまう。できればGPUモード使いたいのでここももうちょっと調べてみよう。